
全体の流れ
まずはデータ分析の流れを確認します。
大きく以下の手順で進めます。
効率的に進めるためには「1. 目標を明確にする」と「2. データを集める」を丁寧にやることが重要です。
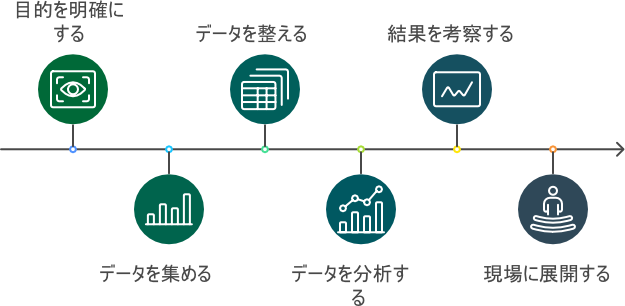
- 目的を明確にする
- データを集める
- データを分析できる形に整える
- データを分析して結果を得る
- 結果から考察する
- 現場に展開する
目的を明確にする
データ分析の最重要事項は目的を明確にすることです。
ビジネスでデータ分析を用いるのであれば「解く力」の前に「見つける力」が重要となります。
何をするにしても時間と労力を使うため無駄な分析を避ける必要があります。
これはデータ分析に限った話ではありません。
見込める効果
データ分析は何かしらの効果を得るために実施する手段の一つです。
まずその手段を使ってどのような効果が見込めるのかを考えます。
普段の改善活動にデータ分析を使うだけですので難しく考える必要はありません。
例えば製造部門においては以下のような効果を考えると取り組みやすくなります。
- 規格外れが減る
- 製造時間が短くなる
- メンテナンス回数が減る
- 作業負荷が減少する
私の経験として、作業者負担を減らす取り組みは現場も乗り気であり、巻き込んでスムーズに進められる印象です。
また広い視点で関われる立ち位置の場合、経営的な意思決定に近い方が業務的な意思決定よりも効果が大きくなる傾向にあります。
極端に言えば、新工場建設を判断できる分析は非常に経営にインパクトを与えます。
評価指標を定める
次に見込める効果を定量的に評価できる手段があるか検討します。
もちろん普段の品質検査項目を活用するのもありです。
ここで注意すべきことはデータの精度を意識して評価指標を決めることです。
例えば分析機器からのデータを用いる場合、測定誤差も考慮に入れなければなりません。
色々進めた後、そもそも測定結果がブレるので使えないデータでした!とならないようにしましょう。
データを集める
目的が決まればデータを集めます。
目的の次に重要な項目だと考えています。
ここで伝えたいのはデータの意味を十分に理解することが重要だということです。
データ間の時刻を考慮する
配管中を流体が移動するプロセス産業においてデータの時刻は重要データです。
特に連続プロセス製造の工程では意識する必要があります。
例えば「製造時の配管内の液温」と「製品の粘度」の関係を調べたいとします。
温度計の位置とサンプリングの位置が離れている場合、その時刻差を考慮しなければなりません。
この場合は流量とサンプリング時刻から逆算し、どの時刻の温度データを使用すれば良いか予測すれば正確性が増します。
サンプリング位置近くに新たな温度計を取り付ける方法もあります。
人によるバラツキを取り除く
1つ前の「データ間の時刻を考慮する」にて取り上げたサンプリングを人が行っていたとします。
活用する温度データはサンプリング時刻から逆算するため、人によるバラツキはデータの信頼性を極端に下げます。
サンプリングのタイミングは統一されているでしょうか?
そのルールが守られているでしょうか?
自動で記録されている場合、記録のトリガーは何なのでしょうか?
私自身、記録された数値のみを当てにして失敗した経験があります。
「現場」「現物」「現実」を重んじる三現主義の考え方はここでも生きてきます。
分析機器を疑う
温度や圧力、流量などのプロセスデータの他に、粘度や密度など分析機器を使用したデータもよく使用します。
その際には以下に示すような項目を事前に調査しておきましょう。
特に品質管理項目ではない新たな測定指標を使う場合は注意が必要です。
データを加工、分析する
今回、私が伝えたかったのはこれまでお伝えした内容が全てです。
ここからは専門家や便利なソフトウェアの力を借りることもできます。
一方でどれだけ優秀な人やソフトを使用しても目的やデータが悪ければ宝の持ち腐れとなってしまいます。
データを分析できる形に整える(前処理)
データ分析で時間を費やすと言われる工程がデータの加工です。
ここでは不要データ、破損データ、穴あきデータなど分析の邪魔になる要素を削除します。
クレンジングという言葉が有名です。
80~100℃で推移させる温度計のデータ群に1000℃のデータが誤って含まれていた場合、例えば平均値が異常に高くなります。
その際は1000℃を測定した時刻のデータのみ削除します。
他にも手入力している温度が”百度”と文字で書かれていたら”100℃”に修正します。
ここでは極端な例を挙げましたが、こうした分析の邪魔だな……と思うデータを削除したり修正したりする工程です。
- 欠損値補完
- 外れ値除去
- 重複の削除
- ダミー変数化
- 標準化
- 文字列の結合、抽出、置換、形式統一
- 日付の要素取り出し、差分
データを分析して結果を得る
果てしないデータの準備を終えると分析工程に移ります。
まずはExcelの機能を使って分析するだけで良いと思います。
統計的な知識はもちろん必要であり、数式の理解は今後必要となります。
ただ、まずはExcelの自動機能を活用することでデータ分析を最後まで実施できるようになりましょう。
- 代表値を見る(平均、最大、最小、中央、最頻)
- ピボットテーブルで層別する
- グラフで可視化する(折れ線グラフ、棒グラフ、ヒストグラム)
- 変数間の関係を見る(散布図、箱ひげ図、ヒートマップ、バブルチャート)
Excelで作成可能なグラフについては以下の記事で解説しています。

注意点として以下のような分析にならないようにします。
特に分析モデルを複雑にして精度を求めることでブラックボックス化します。
ビジネス用途の場合はブラックボックス化した時点で採用が見送られる恐れもあり、ランダムフォレストなど説明性があるモデルが必要となることも多々あります。
| 避けたい分析結果 | 例 |
|---|---|
| 意思決定に役立たない | 材料の発注が1週間前なのに3日前の需要を予測している 機器異常検知したときには既に修理ではなく交換しなければ直らない 気温が80℃であれば収率が上がるなど物理的に不可能な対策である |
| 意思決定に役立つが使えない | 機器の異常を検知したがどこが悪いのか判断根拠がない 10年前の需要データを基に需要予測をしている |
| 意思決定には使えるが現場に拒否される | 勘と経験で非常に精度が良いため不要と言われる 現場を知らない人間の分析結果など当てにできない |
分析の経過は現場と共有する
分析中は出来る限り展開する現場と進捗を共有しながら進めましょう。
急に結果だけを受け取ると「押し付けられた」ような感じがして感情的に受け入れづらくなる恐れがあります。
これは突然自分の業務を(そのつもりが無くても)否定された気分にさせてしまうためです。
一度芽生えた心理的な抵抗は取り除くのに苦労します。
結果から考察する
分析した結果を考察して次の展開を考えます。
ここで重要となるのが実際の製造工程を理解したうえでの考察です。
こうした製品の知識、設備の知識など分析対象に関する特有の知識をドメイン知識と言います。
そのため一人で考えるのではなく周りを巻き込んで考えるのもありです。
現場に展開する
データ分析から得られた知見を現場に展開しなければビジネスとして意味がありません。
その際には結果を現場に「使わせる力」が重要となります。
参考資料
・最強のデータ分析組織
大阪ガスの中で一からデータ分析組織を作りあげ、多くの実績を上げて外部からも注目されるようになった経験を綴った書籍です。
これからDX推進を進めていこうと考える製造業の方にオススメです。

最強のデータ分析組織 なぜ大阪ガスは成功したのか
www.amazon.co.jp
オススメ書籍
・付加価値ファースト
旭鉄工による設備の稼働状況を可視化してムダを削減・効率化した事例です。
更にこのIoTシステムをサービス化し、i Smart Technologiesという会社を立ち上げることまで成功しています。
製造業に携わっているなら誰もが読んでおくべき数少ないDX成功企業の事例です。

付加価値ファースト 〜常識を壊す旭鉄工の経営~
www.amazon.co.jp
・小説 第4次産業革命
自社を想像して、ヒト・モノ・カネの動きが詳細に把握できますか?
新規ライン立ち上げや急な変更が起きた時に原価への影響を見積もれますか?
多くの業種で直面するDXの重要性や、それに対応する過程をドラマ仕立てで描かれた小説です。

小説 第4次産業革命 日本の製造業を救え!
www.amazon.co.jp



{kind=link}