
異常データの特徴
まずは異常検知に必要な異常データについて基本事項を押さえておきます。
異常データは少ない
製造において異常状態が発生する頻度は限られており、ましてや機器の故障データは皆無に近い場合もあります。
そうした異常頻度の低さから異常データを集める作業ができません。
また異常の要因は様々であり、網羅したデータを用意することは至難の業です。
そのため基本的に教師なし学習を採用します。
具体的には”正常データと違う”ことを検知します。
静的と動的な異常
異常データには”静的な異常”と”動的な異常”の2種類があります。
”静的な異常”は各データ間に順序性等の関係がないものを指します。
”動的な異常”は時系列データのようにデータ間に順序性等の関係があるものを指します。
外れ値で検知する
普段のデータの分布から外れるような値(外れ値)を検知して異常と判断します。
個々のデータ点で見ることができるため、後述する変化点や区間での検知よりも比較的扱いやすい手法です。
ホテリング法
ホテリング法は古くからある統計的な手法です。
正常データの平均や分散を使って異常度という指標を算出し、新たなデータが異常度の取りうる範囲に収まっているかで正常/異常を判断します。
異常度
$$ a(x)=\left(\frac{x-μ}{σ}\right)^{2}$$a(x):異常度、x:新たなデータ、μ:正常データの平均、σ:正常データの分散
異常度がカイ二乗分布という形状の取りうる範囲であることが分かっており、カイ二乗分布からの外れ具合で見ています。
データが正規分布であると仮定した考え方で、正常状態が正規分布ではないデータ・複数の正常状態が組み合わさったデータには適用できません。
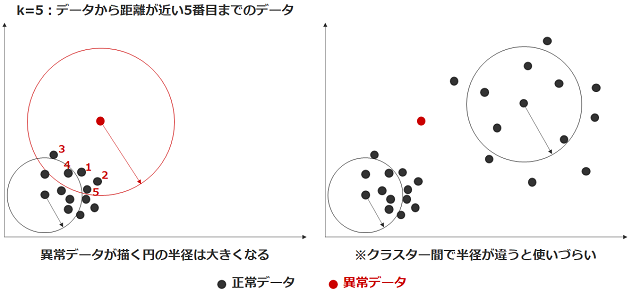
k近傍法
近傍法は、あるデータ点から他データ点までの距離が一定以上離れているときに異常値とみなします。
中でも、あるデータからk番目に近いデータまでの距離を調べるような手法をk近傍法と呼びます。
距離で見ているため、正常データ群(クラスター)ごとに正しい距離が大きく異なる場合には適用できません。
こうした場合には次で解説するLOFが使われます。
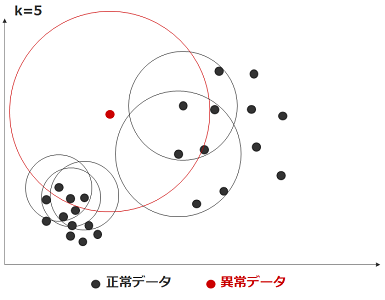
LOF法(局所外れ値因子法)
LOFは先に解説した近傍法に似た考え方で、データの距離ではなく密度で考えます。
つまり、あるデータからk番目に近いそれぞれのデータの密度と比較します。
添付イメージだと、赤丸の半径と黒丸の半径を比較しています。
正確には局所密度という距離の逆数の指標が用いられています。
One-Class SVM
One-Class SVMでは、分類の機械学習手法の1つであるサポートベクターマシン(SVM)異常検知に応用しています。
具体的には原点付近に近いデータを異常とみなします。
そのためにまず正常データを原点から離す操作(写像)を行います。
例えば2次元では正常/異常を分類できないデータでも、3次元のような別の角度から見て正常/異常を検出できるようにしています。
この時カーネルトリックと呼ばれる手法が用いられています。
変化点で検知する
普段のデータの傾向が変化したことを検知して異常と判断します。
時系列予測モデルからの乖離
事前に時系列予測モデルを作成し、実際のデータとの差が大きくなった点を変化点として検出できます。
つまり予想と違う=異常と判断しています。
例えば (予測値-実測値)2 を指標として用います。
累積和法
累積和法では閾値を設け、その閾値から離れた値を次々に足し合わせた時の値(累積和)で変化点と判断する手法です。
Change Finder
時系列のデータには外れ値と変化点が混ざっています。
Change Finderは多数の外れ値処理を行うことで変化点のみを見つける手法です。
具体的には外れ値である可能性を表す外れ値スコアという評価指標を求め、その推移を見ています。
以下のようなフローを経ることで変化点を際立たせて検出することができます。
- 外れ値スコアの推移を求める
- 外れ値スコアの推移に対して移動平均をとり平準化する
- 再度外れ値スコアの推移を求める
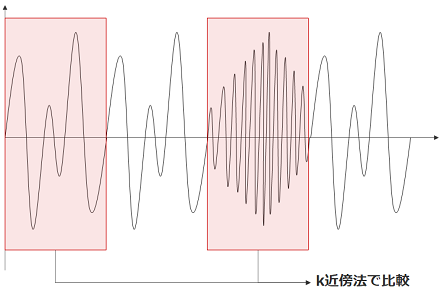
異常な区間から見つける
時系列データをある区間に区切り、正常データとの違いを見つけます。
区切ったデータはk近傍法を用い、正常データと半径が異なる場合に異常と判断します。
データの再現性で判断する
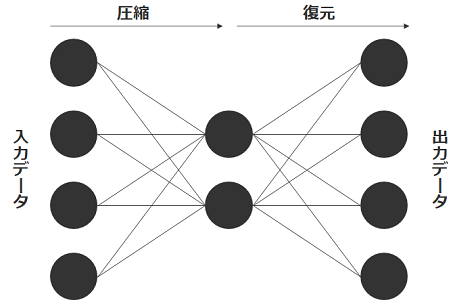
ニューラルネットワークのアルゴリズムの1つにオートエンコーダーがあります。
オートエンコーダーは入力データを一度圧縮し、再度元のデータへ戻せるようなパラメータを学習します。
学習時には入力データと再構成された出力データとの差を最小化するように学習されます。
異常検知においては学習したモデルにデータを入力し、再現できれば正常データ、再現できなければ異常データとして判断します。
オススメ書籍
・化学のためのPythonによるデータ解析・機械学習入門
データ分析に必要な最低限の知識を解説したうえで、化学プラントで得られるデータの扱い方が紹介されています。
脱ブタン塔や排煙脱硝装置を例に取り上げられておりイメージしやすくなっています。
プロセス管理に異常検知手法を用いた例も取り上げられています。
 | 金子 弘昌 |本 | 通販 | Amazon")
化学のためのPythonによるデータ解析・機械学習入門
www.amazon.co.jp
・化学、化学工学のための実践データサイエンス
化学プロセスで得られるデータの前処理や変数選択、可視化、機械学習と1冊で体系的に学べる書籍です。
少しデータ分析を実施したことがある中級者向けの書籍ですが、化学はじめプロセス製造に携わる方なら是非とも読んでおきたい書籍です。

化学・化学工学のための実践データサイエンス ―Pythonによるデータ解析・機械学習
www.amazon.co.jp
・データ分析のための数理モデル入門
データ分析で用いられる様々な手法が紹介されており、それぞれが表す意味をよく理解できます。
どのような手法があるのか体系的に学んでおきたいときにオススメの書籍です。
異常検知で使われるような要素も多く取り上げられています。

データ分析のための数理モデル入門 本質をとらえた分析のために
www.amazon.co.jp



{kind=link}