
YOLOとは?
利用の前に、まずはYOLOについて簡単に解説します。
YOLOの基礎知識
YOLOはYou Only Look Onceの略で、物体検出のための深層学習ベースのアルゴリズムの1つです。
その名の通り、画像を一度だけ見て物体を検出する特性があります。
YOLOの特徴は一定水準の精度を保ちつつも高速・軽量に動作することです。
YOLOv8の特徴
YOLOは2015年に初期バージョンが公開され、2023年1月にv8が公開しています。
これまでのモデルよりも少ないパラメータで高い精度を誇っています。
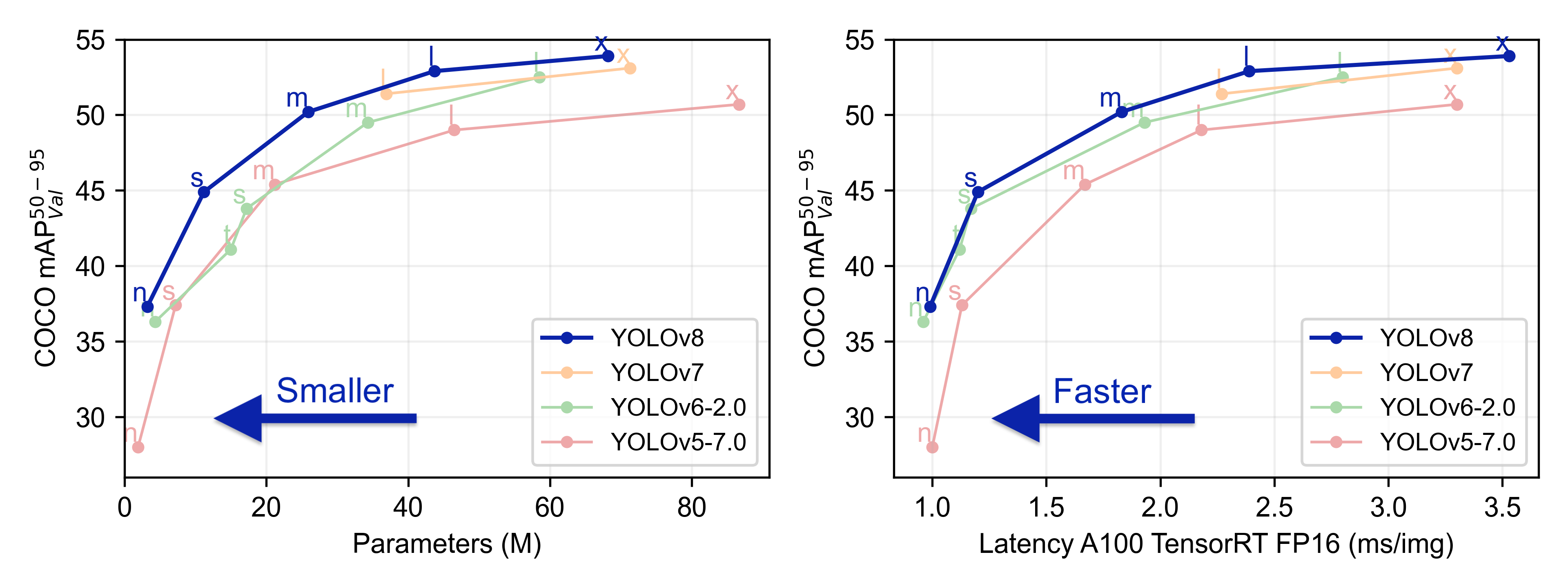
学習に使われているデータ
YOLOv8にはCOCOやImageNetなどの代表的なサンプルデータを用い、既に学習済みのモデルが公開されています。
これを利用することですぐに物体検出を実施できます。
詳しくは公式ドキュメントのDatasets Overviewより確認できます。
画像認識の準備
まずは画像認識の準備を行います。
仮想環境の構築
ultralyticsライブラリは、インストールの過程で非常に多くの関連ライブラリをインストールします。
既にある自分のPython実行環境に悪い影響を与える可能性がありますので、仮想環境を作って影響を無くすことをオススメします。
以下に最低限必要なコマンドを載せておきます。
python -m venv envenv\Scripts\Activate.ps1詳細の手順は以下で解説しています。

ライブラリのインストール
以下のコマンドでUltralyticsライブラリをインストールします。
pip install ultralytics画像認識してみる
ここからは学習済みモデルを使って実際にYOLOv8で画像認識を試してみます。
YOLOv8は、有名な物体検出だけでなく画像分類やセグメンテーションと3種類の手法を利用できます。
各項に分けて紹介していますが、実はモデルの種類を変更するだけでコードは変わりません。
また、学習済みモデルは自動でダウンロードしてくれます。
model = YOLO('ここを変更するだけ') # load an official model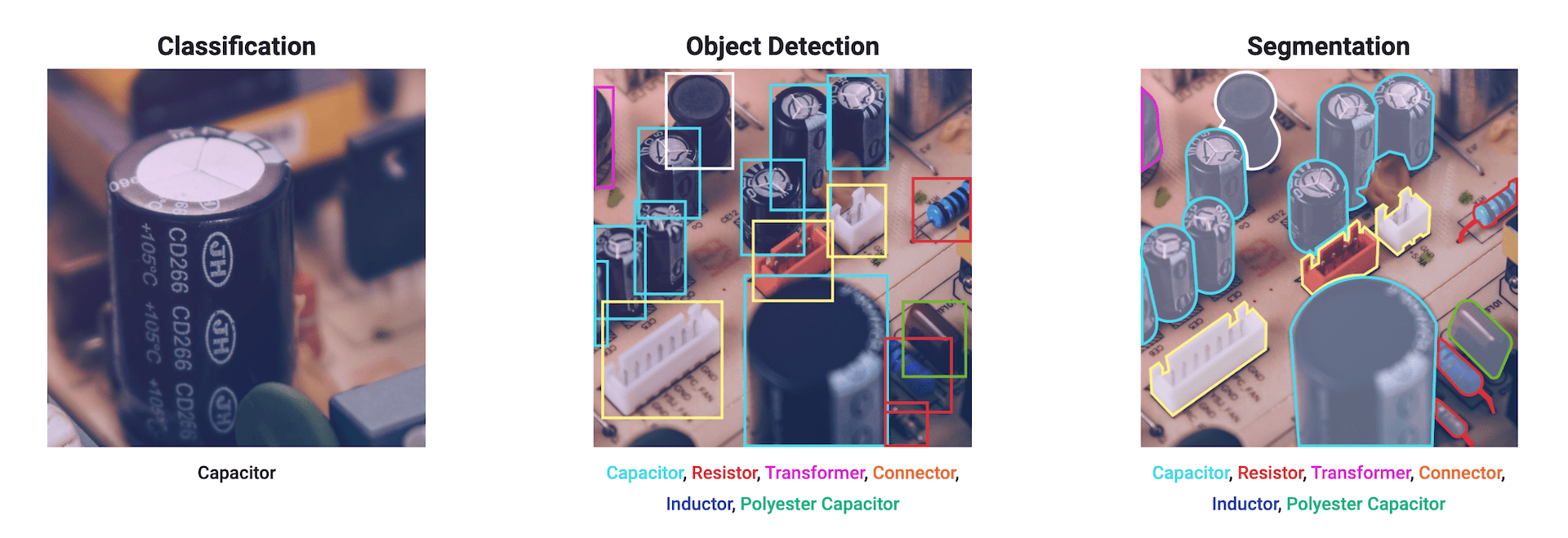
使用する画像
画像サンプルとして有名な人やバスが載った画像を利用します。
コード中にURLを記載しています。
事前にダウンロードの必要はなく、コード実行時に自動でダウンロードしてくれます。

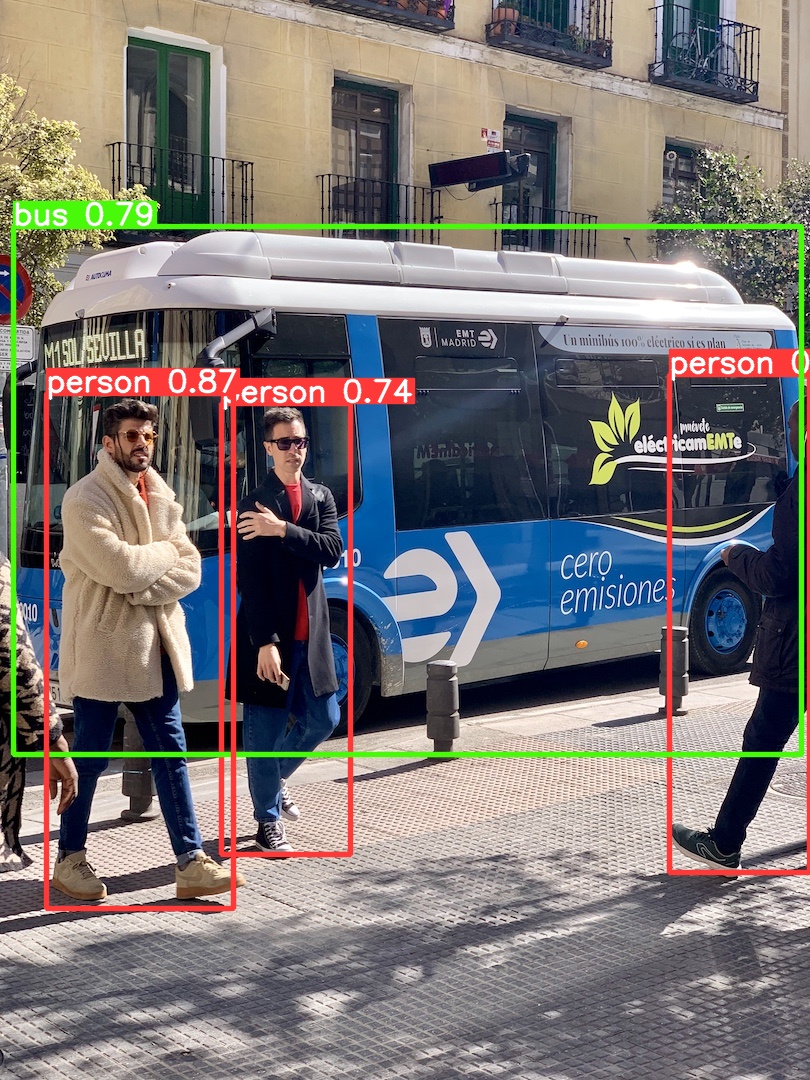
物体検出(Detection)
まずは物体検出を実行してみます。
from ultralytics import YOLO
# Load a model
source = "https://ultralytics.com/images/bus.jpg"
model = YOLO('yolov8n.pt') # load an official model
# Predict with the model
results = model.predict(source, save=True, imgsz=320, conf=0.5)モデルの性能はYOLOv8n<YOLOv8s<YOLOv8m<YOLOv8l<YOLOv8xと増加しますが、反面、学習や推論に時間がかかってしまいます。
モデルの性能の詳細は公式サイトより確認ください。
コードを実行すると、以下の出力が得られます。
画像分類(Classification)
次に画像分類を実行してみます。
from ultralytics import YOLO
# Load a model
source = "https://ultralytics.com/images/bus.jpg"
model = YOLO('yolov8n-cls.pt') # load an official model
# Predict with the model
results = model.predict(source, save=True, imgsz=320, conf=0.5)モデルの性能はYOLOv8n-cls<YOLOv8s-cls<YOLOv8m-cls<YOLOv8l-cls<YOLOv8x-clsと増加しますが、反面、学習や推論に時間がかかってしまいます。
モデルの性能の詳細は公式サイトより確認ください。
コードを実行すると、以下の出力が得られます。
画像の上部に検出した物体と、その確率が示されています。

セグメンテーション(Segmentation)
最後にセグメンテーションを実行してみます。
from ultralytics import YOLO
# Load a model
source = "https://ultralytics.com/images/bus.jpg"
model = YOLO('yolov8n-seg.pt') # load an official model
# Predict with the model
results = model.predict(source, save=True, imgsz=320, conf=0.5)モデルの性能はYOLOv8n-seg<YOLOv8s-seg<YOLOv8m-seg<YOLOv8l-seg<YOLOv8x-segと増加しますが、反面、学習や推論に時間がかかってしまいます。
モデルの性能の詳細は公式サイトより確認ください。

データの中身を確認する
物体検出を題材に、推論結果を見てみます。
from ultralytics import YOLO
# Load a model
source = "https://ultralytics.com/images/bus.jpg"
model = YOLO('yolov8n.pt') # load an official model
# Predict with the model
results = model.predict(source, save=True, imgsz=320, conf=0.5)データの形式
推論結果がresults変数に、リストの中にResultsオブジェクトとして保存されます。
座標と種類を取り出す
どこに何があったのか?を調べるためのコードです。
# results[0]からResultsオブジェクトを取り出す
result_object = results[0]
# バウンディングボックスの座標を取得
bounding_boxes = result_object.boxes.xyxy
# クラスIDを取得
class_ids = result_object.boxes.cls
# クラス名の辞書を取得
class_names_dict = result_object.names
# バウンディングボックスとクラス名を組み合わせて表示
for box, class_id in zip(bounding_boxes, class_ids):
class_name = class_names_dict[int(class_id)]
print(f"Box coordinates: {box}, Object: {class_name}")以下のような出力結果が得られます。
Box coordinates: tensor([ 46.1608, 393.4915, 233.7908, 908.7935]), Object: person
Box coordinates: tensor([ 13.7987, 226.3114, 801.6358, 754.1833]), Object: bus
Box coordinates: tensor([221.3900, 403.3930, 350.0064, 854.4915]), Object: person
Box coordinates: tensor([669.2595, 374.1869, 809.6027, 872.7419]), Object: person
バウンディングボックスに関する出力は座標を示しており、[x1, y1, x2, y2]の形式です。
- x1, y1:バウンディングボックスの左上隅の座標
- x2, y2:バウンディングボックスの右下隅の座標
ちなみに座標はxyxy以外にもxywhやxywyn、xyxhnがあります。
xyxhは左上隅の座標と幅・長さが得られます。
それぞれ末尾にnが付くと、座標とサイズが画像の幅と高さで正規化され、値は0から1の範囲になります。
リアルタイム検出してみる
これまでは事前に準備した画像や動画で画像認識する方法でした。
実はPCのカメラなどを使ってリアルタイムで検出することも出来ます。
OpenCVライブラリを使って映像をキャプチャし、1枚の画像としてとらえ、物体検出を連続的に行っていきます。
import cv2
from ultralytics import YOLO
# Load the YOLOv8 model
model = YOLO('yolov8n.pt')
# Open the video file
cap = cv2.VideoCapture(0)
# Loop through the video frames
while cap.isOpened():
# Read a frame from the video
success, frame = cap.read()
if success:
# Run YOLOv8 inference on the frame
results = model(frame)
# Visualize the results on the frame
annotated_frame = results[0].plot()
# Display the annotated frame
cv2.imshow("YOLOv8 Inference", annotated_frame)
# Break the loop if 'q' is pressed
if cv2.waitKey(1) & 0xFF == ord("q"):
break
else:
# Break the loop if the end of the video is reached
break
# Release the video capture object and close the display window
cap.release()
cv2.destroyAllWindows()新たな画像でAIモデルを学習させる
これまでは既に学習したモデルを使って画像認識していました。
この状態では学習内容に含まれていない物体を検出することはできません。
そこで新たに学習データを用意して、学習させます。
今回は物体検出を例に紹介します。
アノテーションツールlabelImg
学習するには画像データとラベリングデータが必要です。
- 画像データ:目的の物体が載っている画像
- ラベリングデータ:どこにどのような物体が載っているのかを示した情報
画像データに対してラベル付けすることをアノテーションと呼びます。
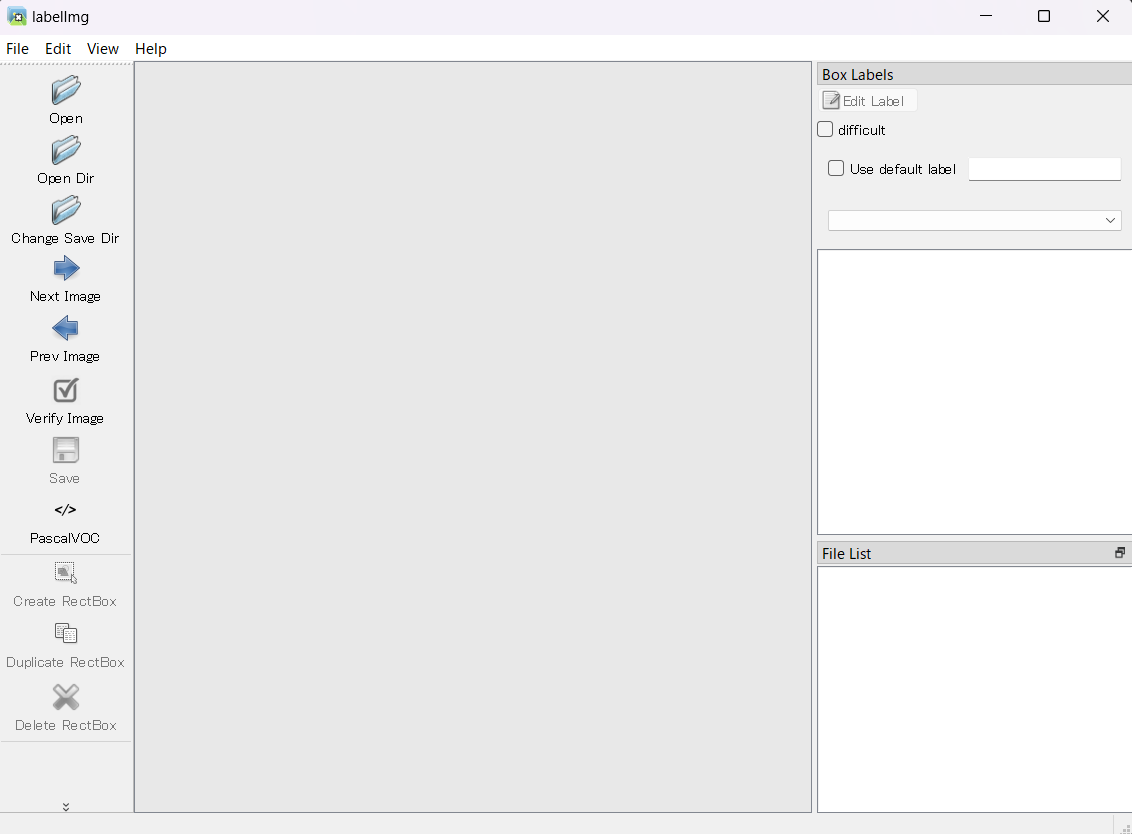
集めた画像データにlabelImgというツールを使いアノテーションします。
pipを使ってlabelImgをインストールします。
pip install labelImgコマンドプロンプトにてlabelImgと入力すると利用できます。
labelImgアノテーション方法
labelImgを開いたら、以下の手順でアノテーションを行います。
- 「Open Dir」で画像データを保存してあるフォルダを指定する
- 「Change Save Dir」でアノテーションしたラベリングデータの保存先を指定する
- ラベリングデータの保存形式が「PascalVOC」や「CreateML」であれば「YOLO」に変更する
- 「Create RectBox」を押した後、画像上でドラッグしながらラベル付けしたい物体の範囲を選択
- 必要な数だけラベル付け出来たら「Save」を押して保存
- 「Next Image」を押して次の画像も同様に実施
操作にはショートカットキーがあり、活用することで効率的に作業できます。
| ショートカットキー | 動作 |
|---|---|
| Ctrl + s | 保存 |
| w | ラベル付け開始 |
| d | 次の画像 |
| a | 前の画像 |
| Delete | ラベルを削除 |
labelImgが落ちる不具合対策
「Create RectBox」を押してラベル付けするときに以下のエラーが表示されてアプリケーションが落ちる場合があります。
Traceback (most recent call last):
File "c:\Users\……\labelImg.py", line 965, in scroll_request
bar.setValue(bar.value() + bar.singleStep() * units)
TypeError: setValue(self, a0: int): argument 1 has unexpected type 'float'
この改善方法についてはGitHub上で議論されています。
データの型が間違っており、関係するライブラリのうち、canvas.pyとlabelImg.pyの中身のコード計4か所にint()を追加します。
- File canvas.py(line526)
from:p.drawRect(left_top.x(), left_top.y(), rect_width, rect_height)
p.drawRect(int(left_top.x()), int(left_top.y()), int(rect_width), int(rect_height))- File canvas.py(line530)
from:p.drawLine(self.prev_point.x(), 0, self.prev_point.x(), self.pixmap.height())
p.drawLine(int(self.prev_point.x()), 0, int(self.prev_point.x()), int(self.pixmap.height()))- File canvas.py(line531)
from:p.drawLine(0, self.prev_point.y(), self.pixmap.width(), self.prev_point.y())
p.drawLine(0, int(self.prev_point.y()), int(self.pixmap.width()), int(self.prev_point.y()))- File labelImg.py(line965)
from:bar.setValue(bar.value() + bar.singleStep() * units)
bar.setValue(int(bar.value() + bar.singleStep() * units))学習させる
アノテーションデータを使ってモデルを学習させます。
1から学習することも出来ますが、例えばmodel = YOLO('yolov8n.pt')で学習済みモデルを選択することによって、モデルの重みをある程度最適化した状態からスタートできます。
また学習するためには.yaml形式のファイルを用意して以下のようにして学習する必要があります。
from ultralytics import YOLO
# Load a model
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
# Train the model
model.train(data='coco128.yaml', epochs=3, imgsz=640)例えばcoco128.yamlファイルは以下のような中身になっています(GitHub参考)。
大量に書いていますが、データの保存先、クラス分類の対応表が載っているだけです。
これを参考に書き換えます。
download: https://ultralytics.com/assets/coco128.zip部分は不要です。
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
# Example usage: python train.py --data coco128.yaml
# parent
# ├── yolov5
# └── datasets
# └── coco128 ← downloads here (7 MB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco128 # dataset root dir
train: images/train2017 # train images (relative to 'path') 128 images
val: images/train2017 # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
names:
0: person
1: bicycle
2: car
3: motorcycle
4: airplane
5: bus
6: train
7: truck
8: boat
9: traffic light
10: fire hydrant
11: stop sign
12: parking meter
13: bench
14: bird
15: cat
16: dog
17: horse
18: sheep
19: cow
20: elephant
21: bear
22: zebra
23: giraffe
24: backpack
25: umbrella
26: handbag
27: tie
28: suitcase
29: frisbee
30: skis
31: snowboard
32: sports ball
33: kite
34: baseball bat
35: baseball glove
36: skateboard
37: surfboard
38: tennis racket
39: bottle
40: wine glass
41: cup
42: fork
43: knife
44: spoon
45: bowl
46: banana
47: apple
48: sandwich
49: orange
50: broccoli
51: carrot
52: hot dog
53: pizza
54: donut
55: cake
56: chair
57: couch
58: potted plant
59: bed
60: dining table
61: toilet
62: tv
63: laptop
64: mouse
65: remote
66: keyboard
67: cell phone
68: microwave
69: oven
70: toaster
71: sink
72: refrigerator
73: book
74: clock
75: vase
76: scissors
77: teddy bear
78: hair drier
79: toothbrush
# Download script/URL (optional)
download: https://ultralytics.com/assets/coco128.zip学習した重みを使う
学習後の重みデータは、runs\detect\train\weightsの中に2つの重みデータが入っています。
- best.pt:学習の過程で最も性能が良かった重み
- last.pt:一番最後に学習したときの重み
学習した重みを設定すれば、後は学習済みモデルで推論したときと同様のコードで推論できます。
from ultralytics import YOLO
source = "https://ultralytics.com/images/bus.jpg" # 自身が検出したいデータの位置
model = YOLO('best.pt') # 学習した重みデータ
model.predict(source, save=True, imgsz=640 conf=0.5)オススメ書籍
・化学のためのPythonによるデータ解析・機械学習入門
データ分析に必要な最低限の知識を解説したうえで、化学プラントで得られるデータの扱い方が紹介されています。
脱ブタン塔や排煙脱硝装置を例に取り上げられておりイメージしやすくなっています。
 | 金子 弘昌 |本 | 通販 | Amazon")
化学のためのPythonによるデータ解析・機械学習入門
www.amazon.co.jp
・Pythonによる時系列分析: 予測モデル構築と企業事例
プロセス製造において時系列データの分析は欠かせません。
どのように時系列予測モデルを構築し、ビジネスへ活用していくかを詳細なPythonコードとともに解説してくれます。

Pythonによる時系列分析: 予測モデル構築と企業事例
www.amazon.co.jp
・PyCaretで学ぶ 機械学習入門
機械学習モデルを構築するのは想像以上に手間がかかります。
その一連の作業を自動化できるPyCaretというライブラリの使い方が分かりやすく解説されています。

PyCaretで学ぶ 機械学習入門
www.amazon.co.jp




{kind=link}