
PyCaretは「データ分析が専業ではないけど実施する」そんな方々にオススメです。
概要
まずはPyCaretについて概要を紹介します。
PyCaretとは?
PyCaretは機械学習のモデル構築プロセスを自動化できる素晴らしいPythonライブラリです。
AutoML(Automated Machine Learning)に分類されます。
機械学習ではモデルの前処理や特徴量エンジニアリング、モデルの選択、パラメータチューニングなど自らコードを書いていると果てしない作業が多く存在します。
PyCaretはこれら作業を自動化してくれます。
データの収集・解釈・施策に集中できる
「データ分析は前処理が殆ど」と言われるほどです。
更にPythonでコードを書くとなると、機械学習モデルの構築も思ったより大変です。
こうした前処理やモデル構築はビジネス課題を解決するための手段に過ぎません。
出来る限り作業を自動化させることで、以下のような作業に集中できます。
- 収集:どのようなデータを取るべきか、どこにセンサーを付けるべきか
- 解釈:分析結果は何を意味しているのか、どの程度の効果が得られそうか
- 施策:分析結果を踏まえた対策の実施、効果の確認、更なる施策の検討
こんなことができる
scikit-learnやXGBoost、LightGBM、CatBoost、spaCy、Optuna、Hyperopt、Rayなど、様々なライブラリの機能を使えます。
このような複数のライブラリをまとめて使いやすくしたものをラッパーと呼びます。
なんと大量のライブラリを組み合わせて回帰や分類、クラスタリング、異常検知、時系列予測が実施できます。
他にもデータの前処理や特徴量生成、webアプリ化などにも対応しており、PyCaretだけで何でも出来ると言っても過言ではありません。
無料!だから凄い
PyCaretのようなAutoMLツールは多いですが、サブスクリプション形式かつ非常に高価なものばかりです。
そんな中、自身で少しコードを書く手間があるものの無料で使えるPyCaretは非常に価値があります。
一方で、市販品の価値は「アプリケーションの使いやすさ」「維持管理の簡単さ」などが挙げられます。
PyCaretは「データ分析が専業ではないけど実施する」そんな方々にオススメです。
| 比較項目 | 市販のAutoML製品 | PyCaret |
|---|---|---|
| 価格 | 年間 数10万~数100万円 (ライセンス次第で数1,000万にも) | 無料 |
| 対象者 | データ分析を専業にする人 (ツール使用頻度が高い) | 他の業務に加えてデータ分析も行う人 (ツール使用頻度が低い) |
| 利用開始速度 | 購入後すぐに利用できる | 自身でコードを書くため時間がかかる |
| 維持管理 | アプリのアップデート管理のみ | ライブラリなどソフトウェアの管理 PCなどハードウェアの管理 |
| モデル精度 | 製品によるが(おそらく)高い | 一定水準の精度は出せる 上を求める場合はカスタマイズが必要 |
| カスタマイズ | 製品のできる範囲に依存する | 自由にコードを書いてカスタマイズ可能 |
事前準備
まずは利用までの準備を行います。
仮想環境の構築
PyCaretはインストールの過程で非常に多くの関連ライブラリをインストールします。
既にある自分のPython実行環境に悪い影響を与える可能性がありますので、仮想環境を作って影響がないようにします。以下に最低限必要なコマンドを載せておきます。
python -m venv envenv\Scripts\Activate.ps1詳細の手順は以下で解説しています。

ライブラリの準備
以下のコマンドでPyCaretライブラリをインストールします。
インストール量が多いため完了までに15分程度かかる場合があります。
pip install pycaret[full]上記コマンドは全てのライブラリをインストールする場合のコマンドです。
個別で種類を選んでインストールするときのコマンドは公式ドキュメントを参照してください。
データの準備
必要なライブラリをインポートします。
今回はPyCaretに保存されている糖尿病進行度に関するサンプルデータを用いて分類の機械学習モデルを構築します。
from pycaret.datasets import get_data
data = get_data('diabetes')オリジナルのデータを使いたい場合はpandasのread_csvなどを用いてdataに保存します。

機械学習モデルの構築
ここから機械学習モデルを構築していきます。
初期化、条件設定
まずは学習環境を初期化します。
targetは目的変数のカラム名、session_idは乱数を固定するための数値です。
from pycaret.classification import ClassificationExperiment
s = ClassificationExperiment()
s.setup(data, target = 'Class variable', session_id = 123)すると今回の学習で用いられるデータの情報や学習条件が出力されます。
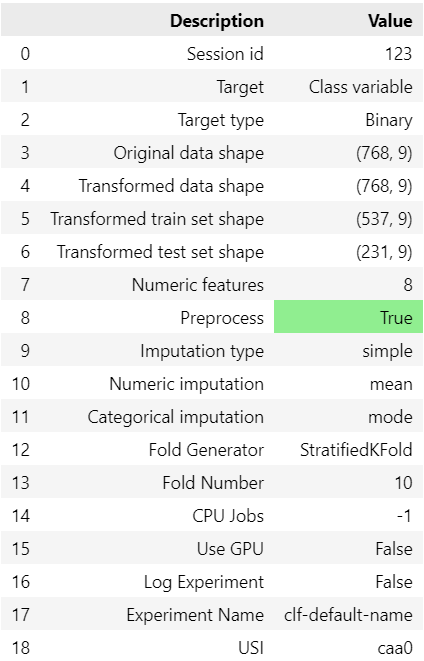
この時、必要に応じてsetupの引数に前処理の条件などを入れておきます。
意識しておきたいデフォルトの内容は以下の通りです。
- 学習と検証データは7:3で分割
- 数字の欠損値は平均値が代入される
- 文字列の欠損値は最頻値が代入される
- 交差検証は10分割の層化k分割交差検証
- GPUは使用しない
詳細のコードは公式ドキュメントを参照してください。
例えば以下のような書き方をします。
s.setup(
data,
target='Class variable',
train_size=0.8, # トレーニングデータのサイズを80%に設定
numeric_features=['Age (years)'], # 数値変数の指定
date_features=[], # 日付変数の指定(この例では無し)
ignore_features=[], # 分析から除外する変数の指定(この例では無し)
normalize=True, # 数値変数の正規化
normalize_method="zscore", # 正規化の方法としてz-scoreを使用
transformation=True, # 変数の変換(例: Box-Cox変換)
transformation_method="yeo-johnson", # 変換の方法としてYeo-Johnson変換を使用
remove_outliers=True, # 外れ値の除去
outliers_threshold=0.05, # 外れ値として扱う閾値
pca=False, # 主成分分析を使用しない
session_id=123
)モデルの選択
次に機械学習モデルを選択します。
PyCaretで使用できる様々なモデルを使って交差検証で評価します。
best = s.compare_models()各モデルのハイパーパラメータはデフォルト値が使用されており、どのモデルが初期の段階で最も良い性能を持っているかを手軽に確認できます。
完了後は用いたモデルや精度が一覧で表示されます。
一番優れている数値にはそれぞれハイライトして表示されます。
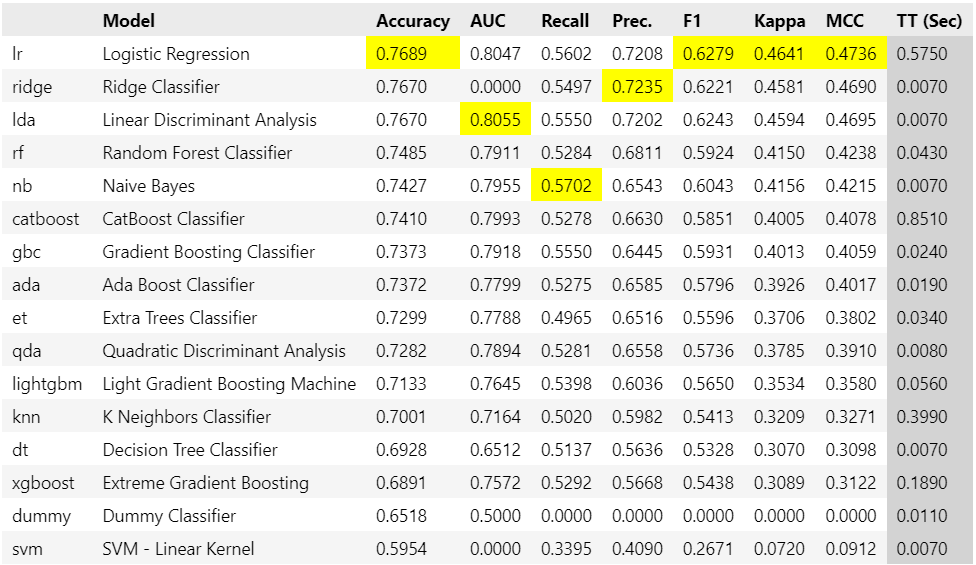
一番正解率(Accuracy)が高いモデル(回帰の場合は決定係数 R2)を以下から確認できます。
今回はロジスティック回帰が選択され、その時のハイパーパラメータも記載されています。
print(best)
ちなみに、モデル選択に使用する評価指標はcompare_modelsの引数にsortを入れることで変更できます。
best = s.compare_models(sort = 'F1') # F1スコアで評価するまた上位n個のモデルを出力したい場合は、compare_modelsの引数にn_selectを入れることで変更できます。
best = s.compare_models(n_select = 3) # 上位3つのモデルを出力モデルの最適化
選択したモデルは、まだデフォルトのハイパーパラメータでしか評価していません。
ここからパラメータの最適化を行います。
tuned_best = s.tune_model(best)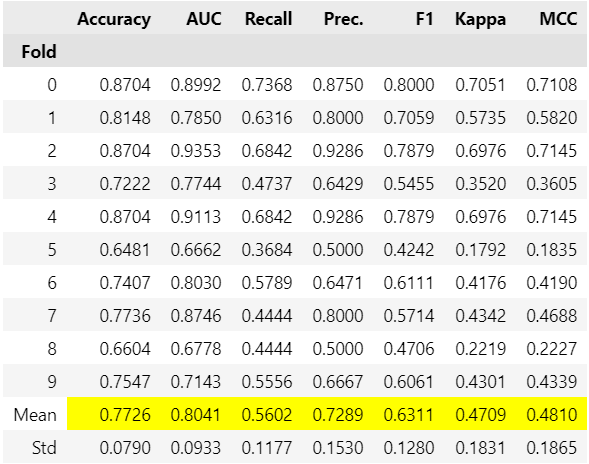
今回は一番正解率(Accuracy)の高いロジスティック回帰が選択され、その時のハイパーパラメータも記載されています。
print(tuned_dt)
モデル選択時と同様に、評価指標は変更できます。
tuned_best = s.tune_model(best, optimize = 'F1')また最適化アルゴリズムはデフォルトがランダムグリッドサーチ(RandomGridSearch)ですが、OptunaをはじめScikit-optimizeやTune-sklearnが選択可能です。
tuned_best = s.tune_model(best, earch_library = 'optuna')しばしばハイパーパラメータチューニングをしても性能が向上しないことがあります。
性能が悪化した場合に入力時のパラメータを採用するよう設定できます。
tuned_best = s.tune_model(best, choose_better = True)モデルの評価
学習したモデルの精度を確認します。
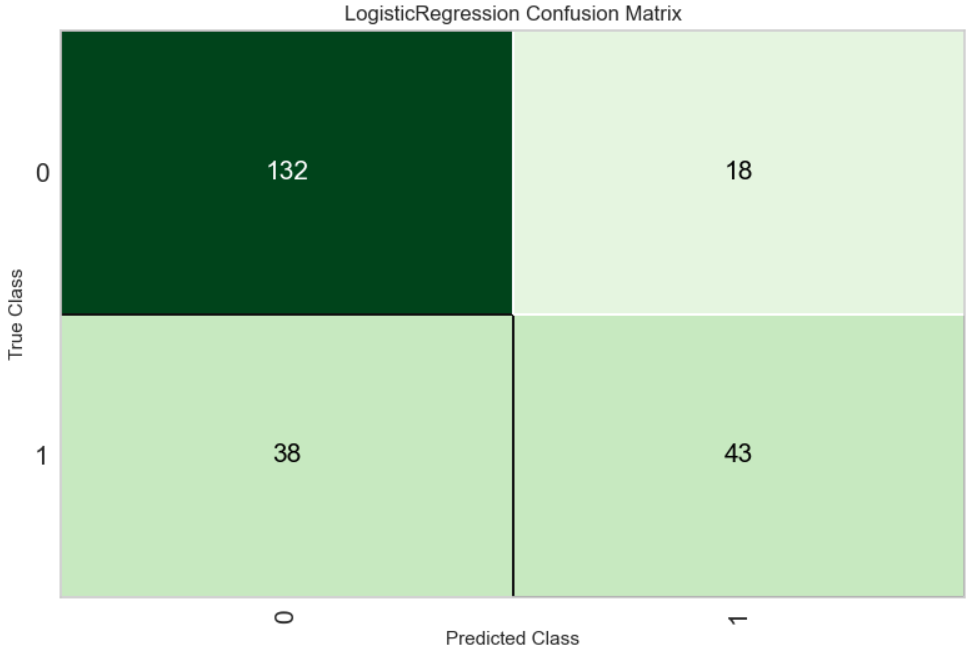
s.evaluate_model(tuned_best)Pycaretは結果の確認画面が特徴的で、ボタンを押すことで目的のグラフや表が表示されます。
今回の例では一番正解率(Accuracy)が高かったロジスティック回帰についての評価結果が表示されます。

任意のものを選択して表示する場合は以下のように指定します。
s.plot_model(tuned_best, plot = 'auc')s.plot_model(tuned_best, plot = 'confusion_matrix')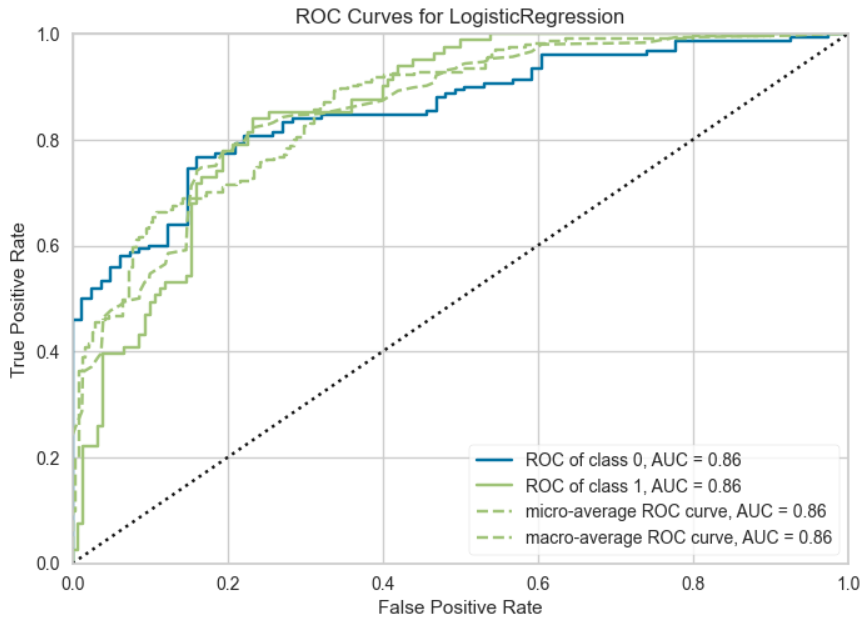
機械学習モデルの運用
最適な機械学習モデルが見つかったら、最後にモデルを利用します。
学習済みモデルを使った予測
最初にsetupでモデルの初期設定をしたとき、学習データと検証データを7:3に分割しています。
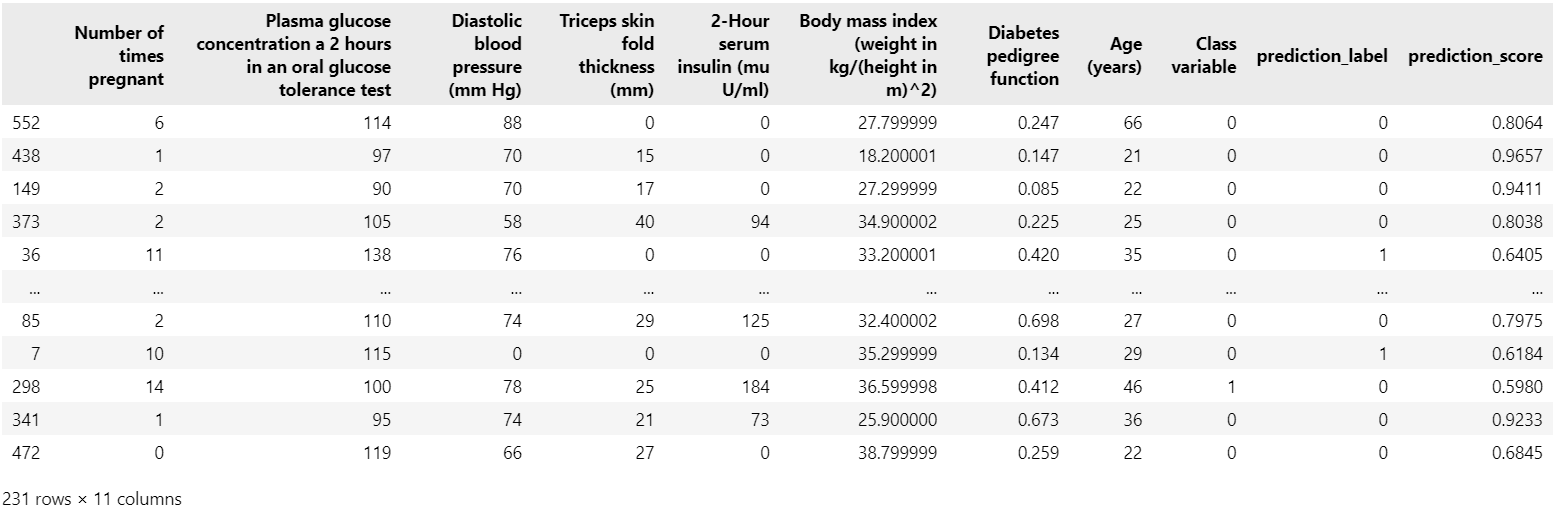
残りの3割のデータで予測をしてみます。
s.predict_model(tuned_best)元のデータの中に、目的変数であるClass variableの予測結果に該当するprediction_labelとその予測確率を表すprediction_scoreというカラムが追加されています。
また、未知のデータでの学習も出来ます。
今回はコードを紹介する目的で、既存のデータをコピーして目的変数のないnew_dataを作っています。
実際には皆さんの手元にある学習していない未知のデータを用いてください。
new_data = data.copy()
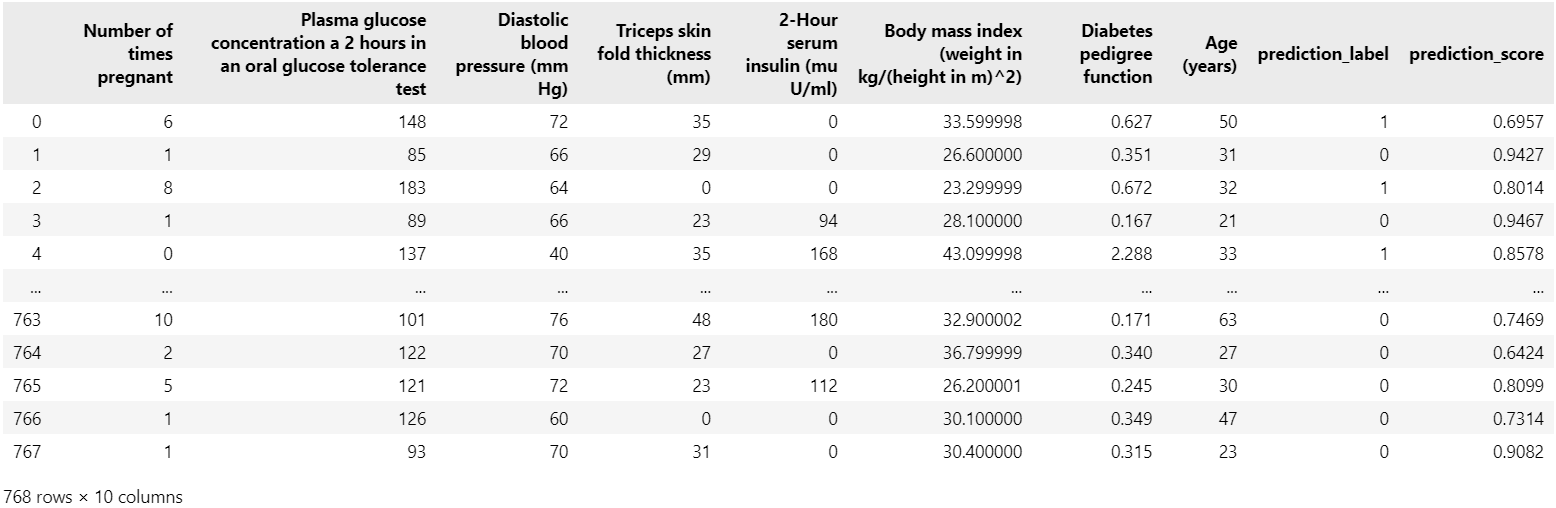
new_data.drop('Class variable', axis = 1, inplace = True)今度は学習済みモデルを使って未知のデータを予測します。
predictions = s.predict_model(tuned_best, data=new_data)
predictions同様にprediction_labelとprediction_scoreというカラムが追加されています。
学習済みモデルはpickle形式(.pkl)で保存することで後から再利用できます。
s.save_model(tuned_best, 'my_best_pipeline')再利用するときはload_modelを使います。
loaded_model = s.load_model('my_best_pipeline')webアプリの作成
なんとPyCaretでは学習済みモデルでアプリも作れます。
Gradioによる予測画面作成
作成したモデルを使って簡単なWEBアプリケーションが作れます。
Gradioというライブラリが裏で動いています。
create_app(tuned_best)出力されるURLをクリックすると、ブラウザで変数の入力欄と出力結果欄が表示されます。
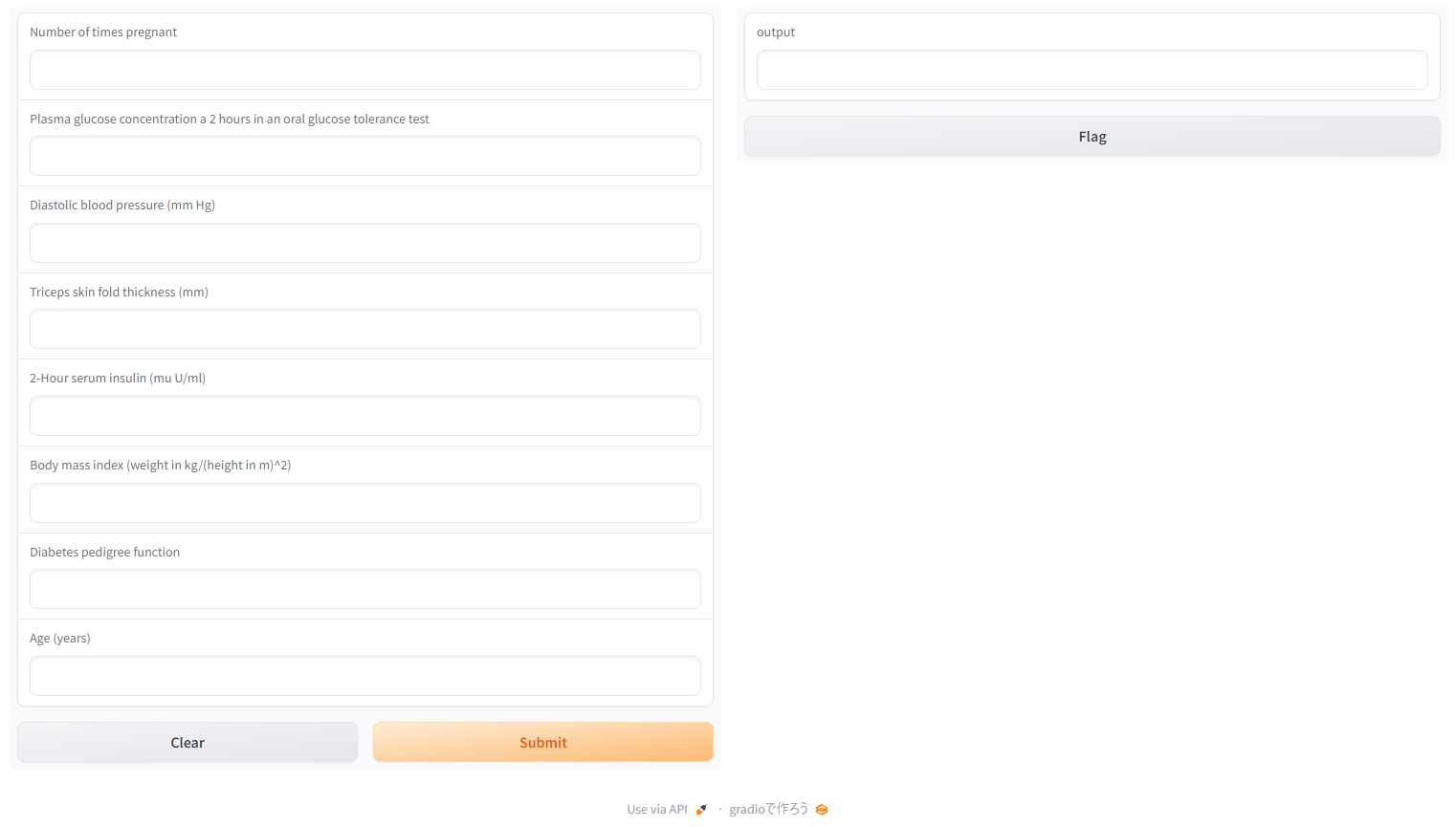
”Flag”をクリックすると、学習に使った変数と出力結果がcsvで保存されます。
基本的にコードを実行中は指定のURLからアクセスできるようになっており、例えばVScodeで開いているPythonファイルを閉じるとURLは効力を失ってアクセスできなくなります。
特定のモデルを選択したい場合
特定のモデルを学習する場合はcreate_modelを使います。
xgboost = create_model('xgboost')使えるモデルとその記号を確認するにはsetupの後に以下のコマンドを入力します。
models()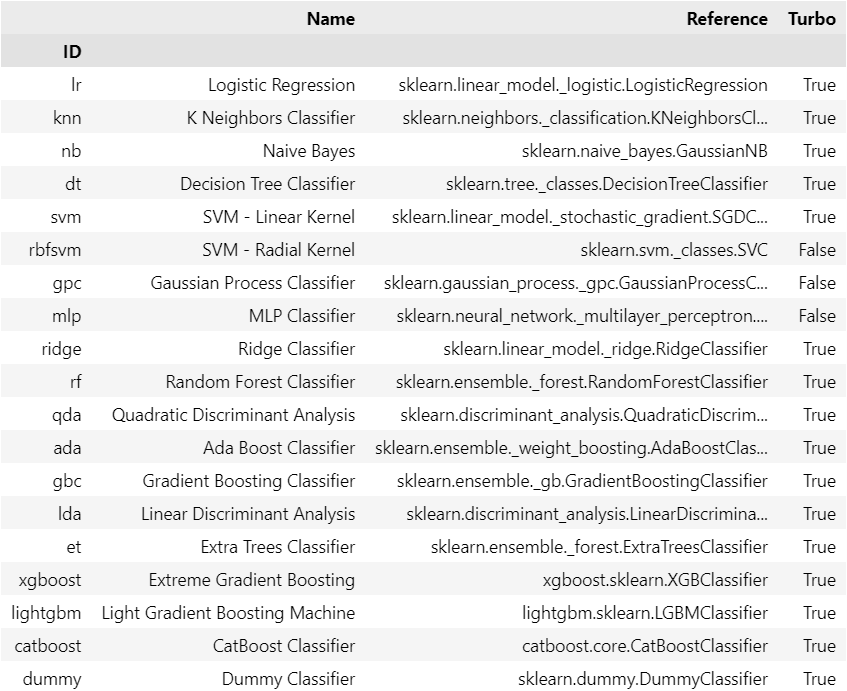
参考資料
・PyCaretで学ぶ 機械学習入門
機械学習モデルを構築するのは想像以上に手間がかかります。
その一連の作業を自動化できるPyCaretというライブラリの使い方が分かりやすく解説されています。

PyCaretで学ぶ 機械学習入門
www.amazon.co.jp
オススメ書籍
・化学のためのPythonによるデータ解析・機械学習入門
データ分析に必要な最低限の知識を解説したうえで、化学プラントで得られるデータの扱い方が紹介されています。
脱ブタン塔や排煙脱硝装置を例に取り上げられておりイメージしやすくなっています。
 | 金子 弘昌 |本 | 通販 | Amazon")
化学のためのPythonによるデータ解析・機械学習入門
www.amazon.co.jp
・Pythonによる時系列分析: 予測モデル構築と企業事例
プロセス製造において時系列データの分析は欠かせません。
どのように時系列予測モデルを構築し、ビジネスへ活用していくかを詳細なPythonコードとともに解説してくれます。

Pythonによる時系列分析: 予測モデル構築と企業事例
www.amazon.co.jp




{kind=link}